OpenClaw使用本地Ollama调用qwen3大模型
这次依旧是虚拟机(Linux)运行OpenClaw server,然后物理机运行Ollama,本地模型使用qwen3:30b
虚拟机:Linux kali 6.16.8+kali-arm64
物理机:Darwin bogon 25.3.0 Darwin Kernel Version 25.3.0
Ollama安装
官网给了一个直接Ollama加载OpenClaw的方法,但是在安装ollama的本地检测是否部署了openclaw,然后启动,这里因为openclaw和ollama不在同一台机器上,所以不用这种方法。
安装好后下载模型,我这里用的是qwen3:30b,因为本地模型肯定是不如在线模型好,尽量选参数量大一点的
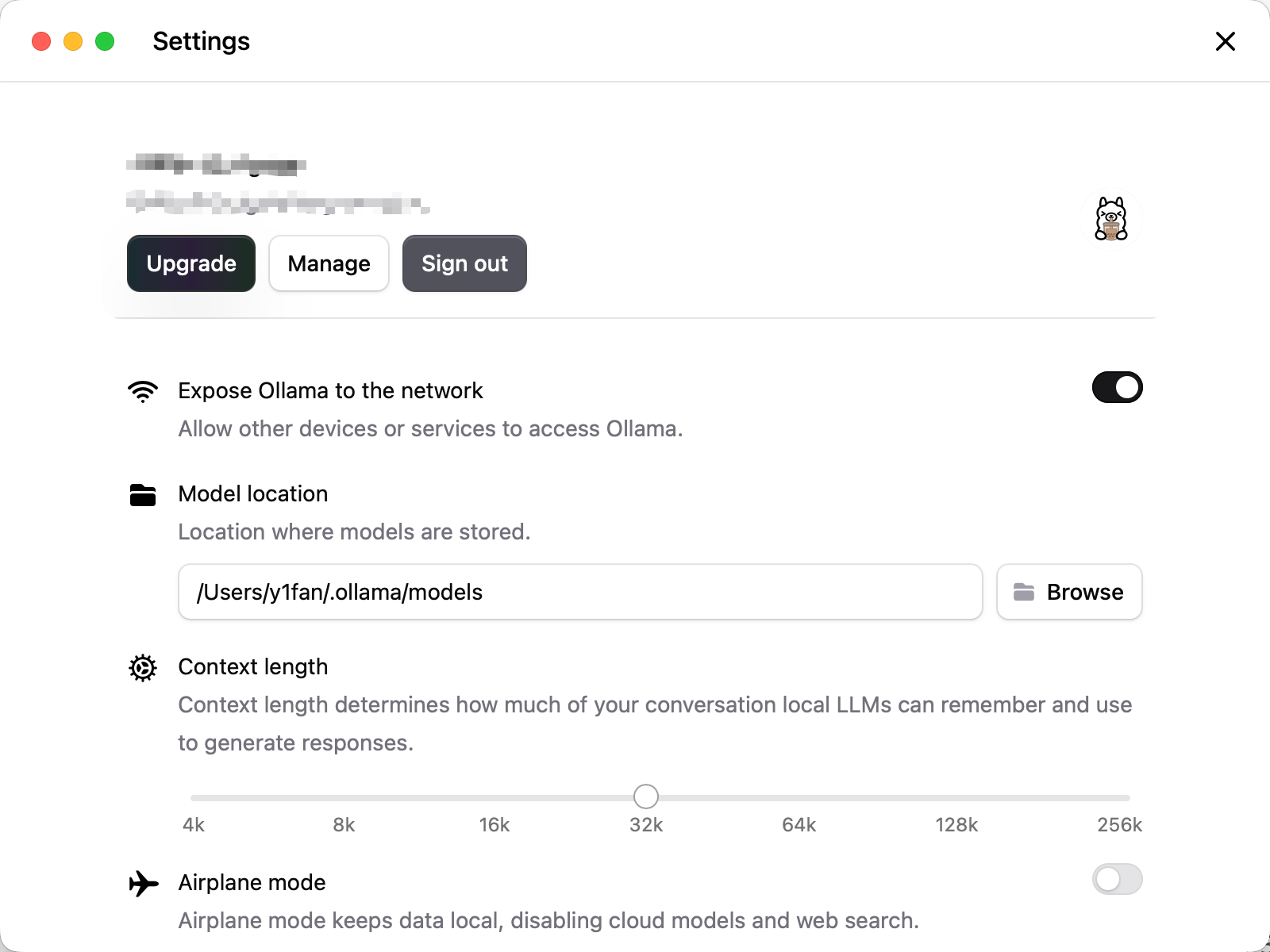
然后设置里面打开网络访问,OpenClaw要求模型上下文窗口≥16000 tokens,而Ollama拉取的基础模型默认上下文窗口仅4096 tokens,所以需要将上下文窗口扩展至32768 tokens
OpenClaw配置
OpenClaw 需要一个API Key来识别 Ollama 服务。由于 Ollama 是本地服务,所以这个 Key 可以是任意字符串
1 | openclaw config set models.providers.ollama.apiKey "ollama-local" |
官方文档给出了,当ollama和openclaw部署在同一个服务器上的时候,设置了OLLAMA_API_KEY就可以自动识别到并且加载到openclaw里,这里没有在同一台机器上部署,所以需要手动添加
官网给了配置文件当中的一段
1 | { |
其实有web界面,可以从web界面修改,打开web界面
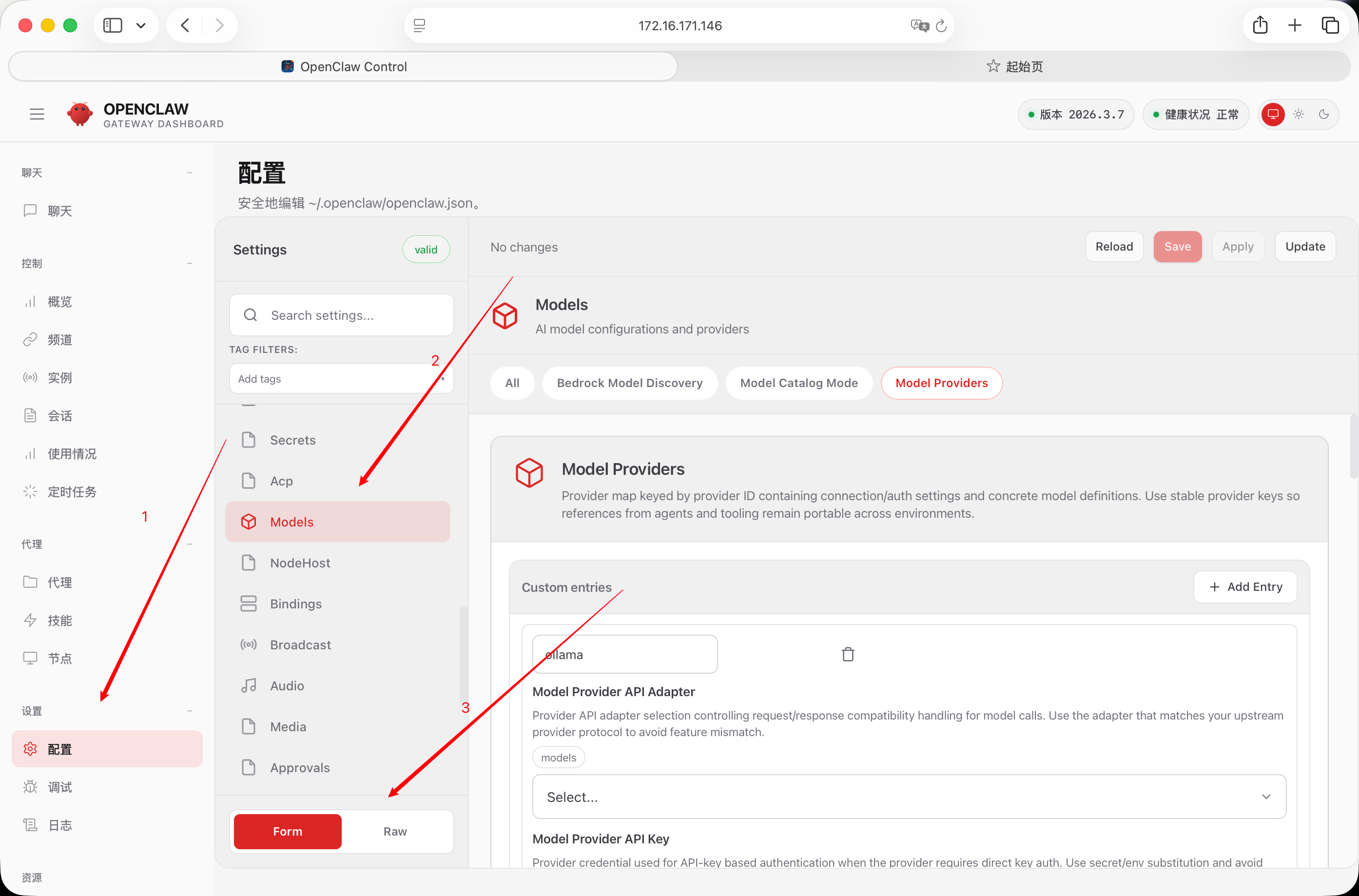
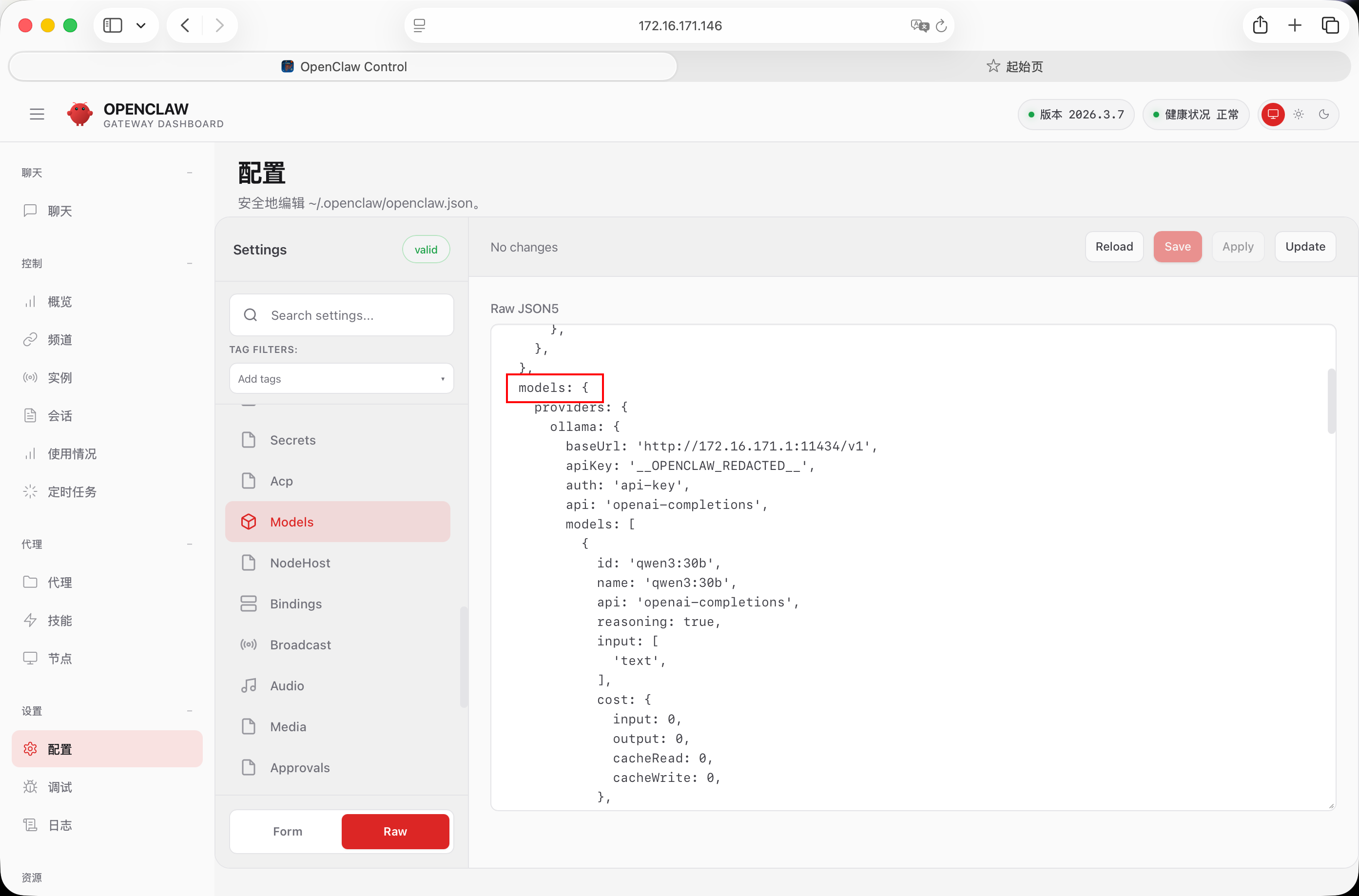
Settings下面Form和Raw可以切换前端界面和原始的json格式,也就是openclaw.json文件里的内容格式,直接翻到models这一栏
我个人理解的这个层级逻辑是:
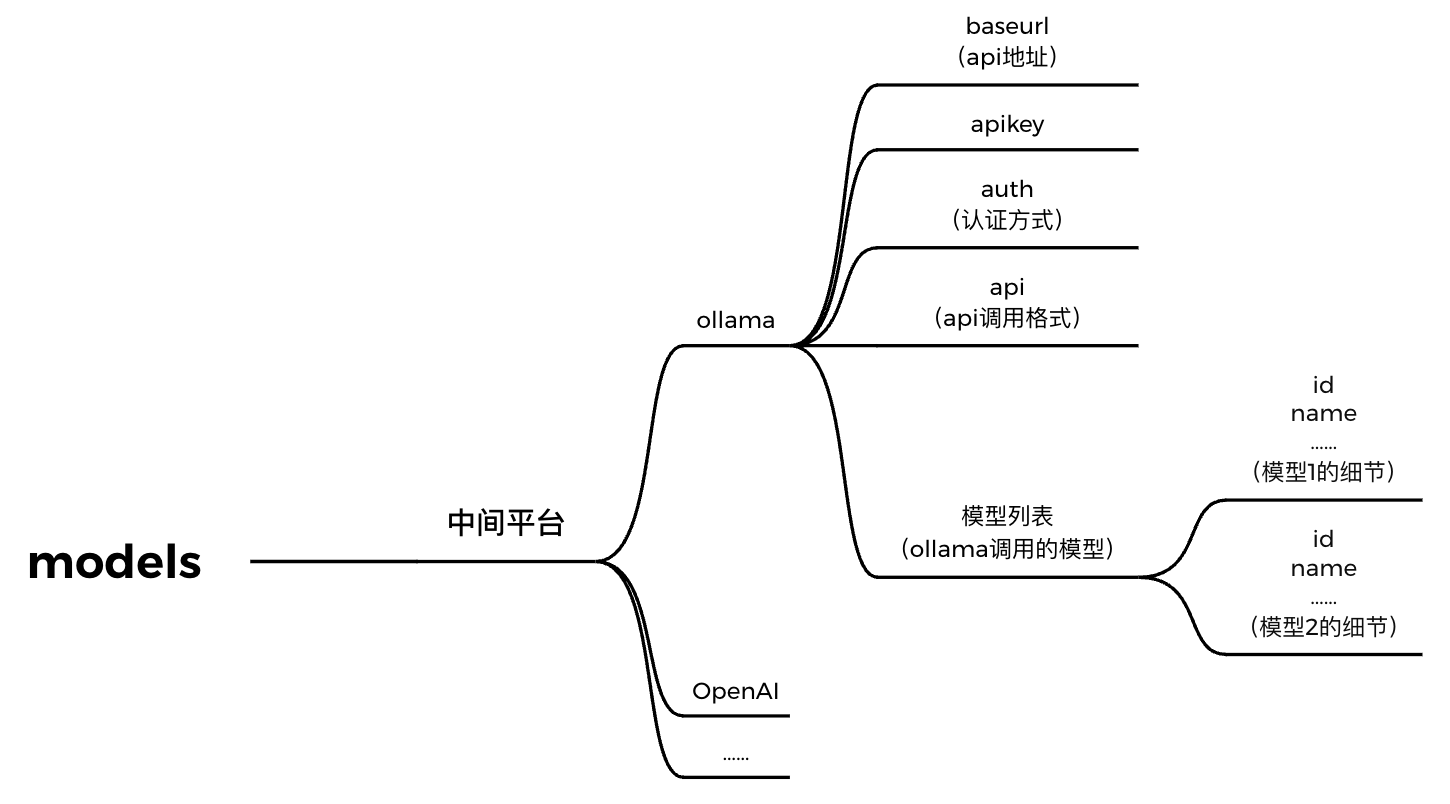
然后就是把json里的配置项和web界面当中的配置项对应起来。
这里第一个内容就是第层的ollama的配置,API Adapter选择openai-completions,API Key就是前面配置的ollama-local
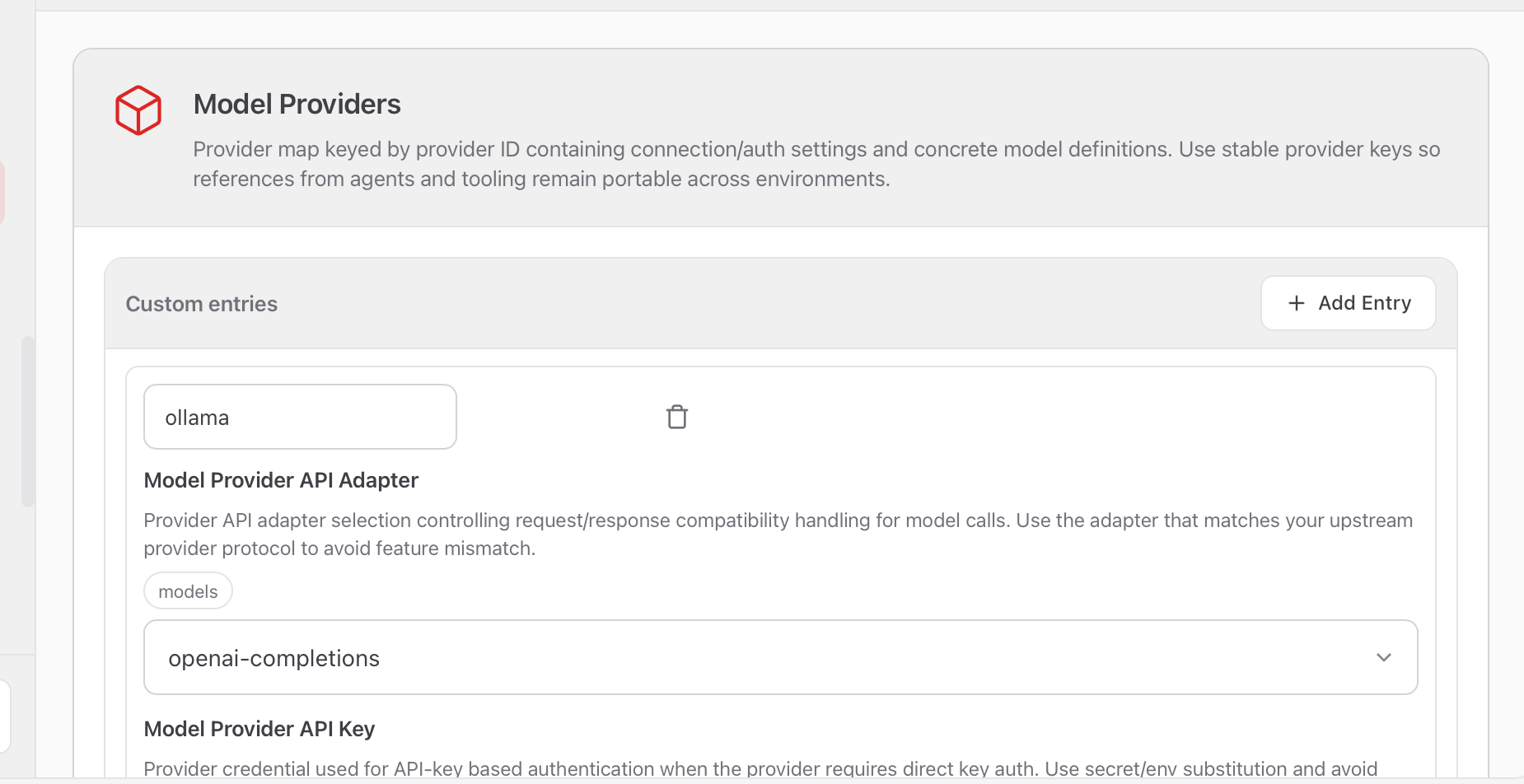
然后Base URL一定是运行ollama的服务器ip
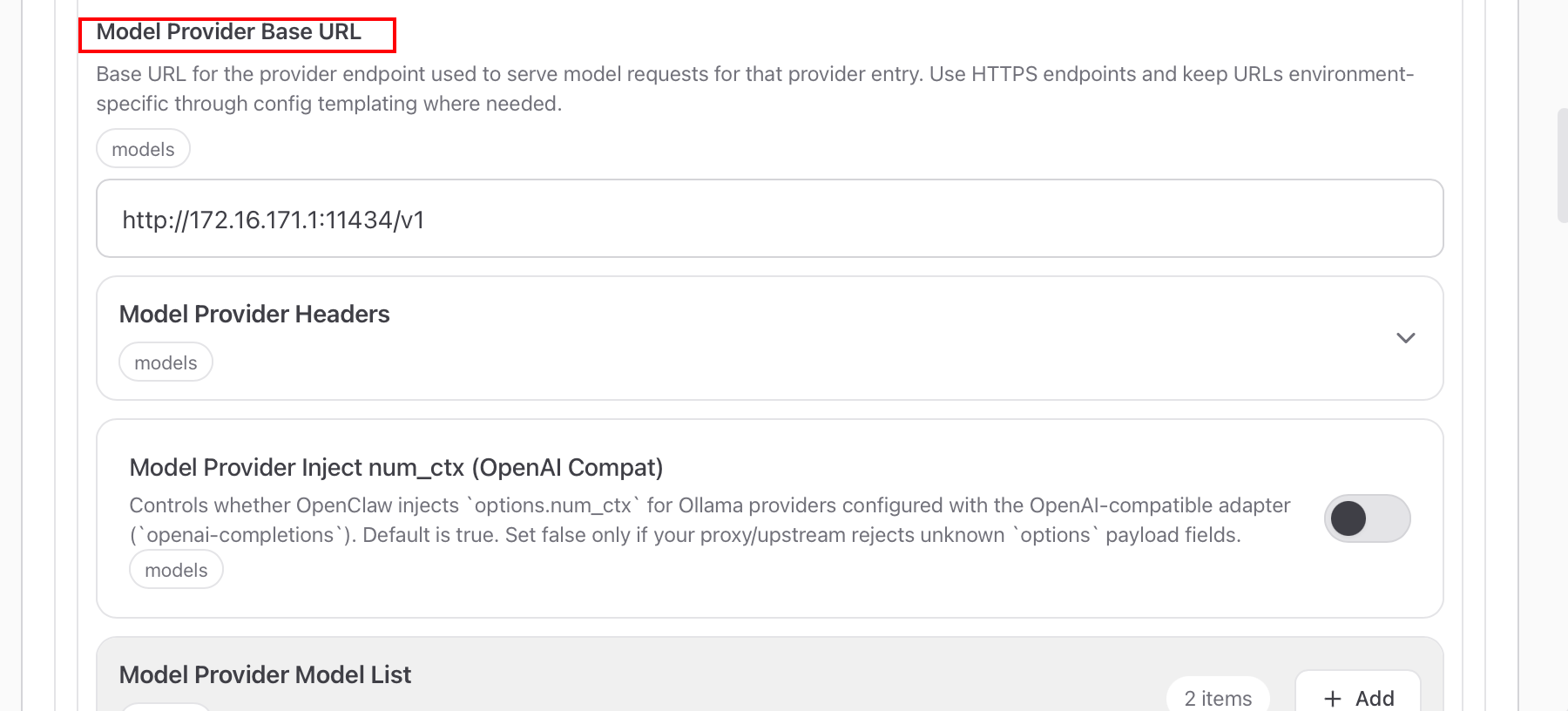
到这步第一层的配置就完成了,然后是第二层对ollama调用的模型进行配置,设置第一个模型,Api还是openai的,Context Windows设置为32768,这里openclaw对Context Windows限制了不能低于16000,然后Cost全部设置为0,因为是在本地运行的模型没有费用。
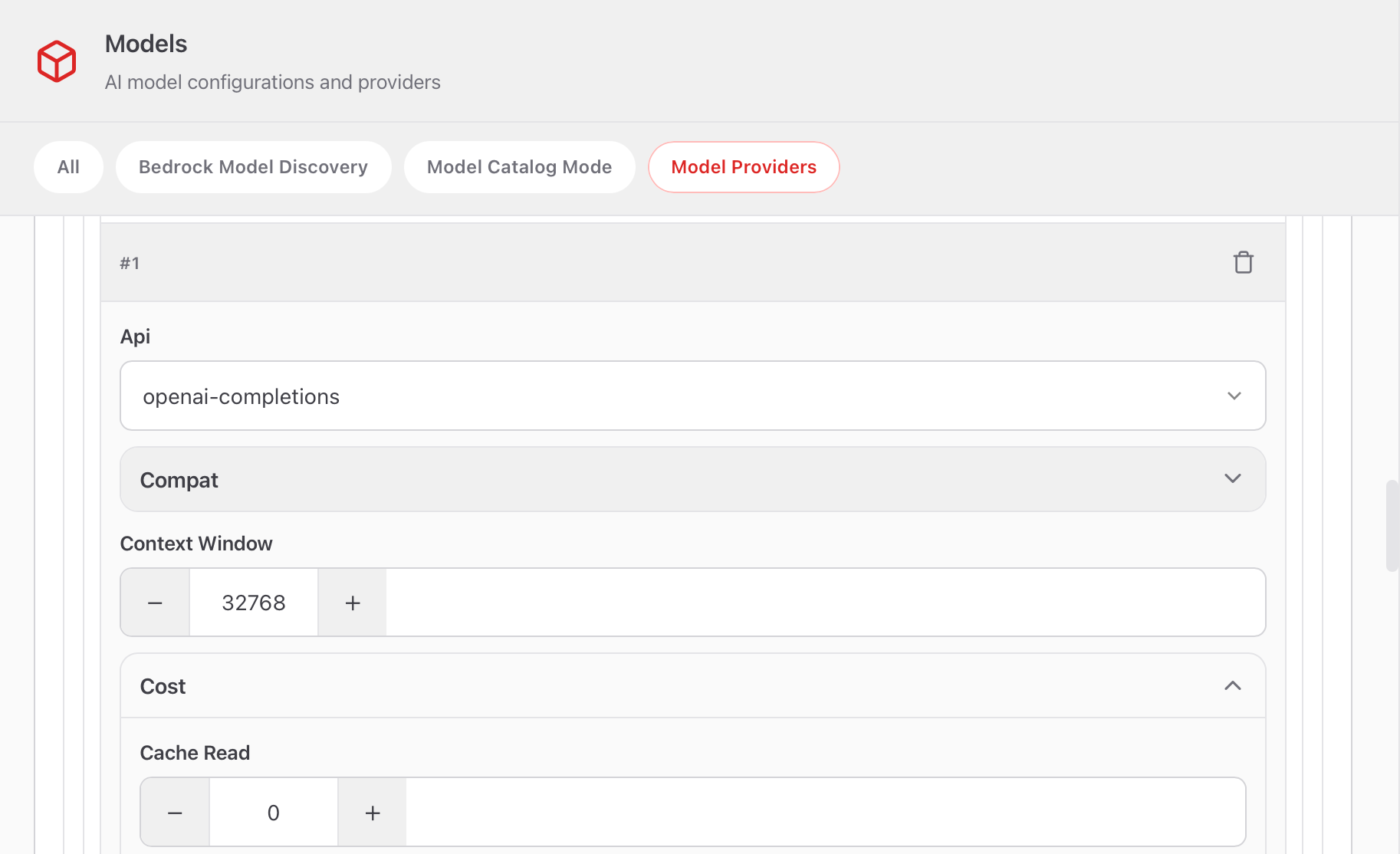
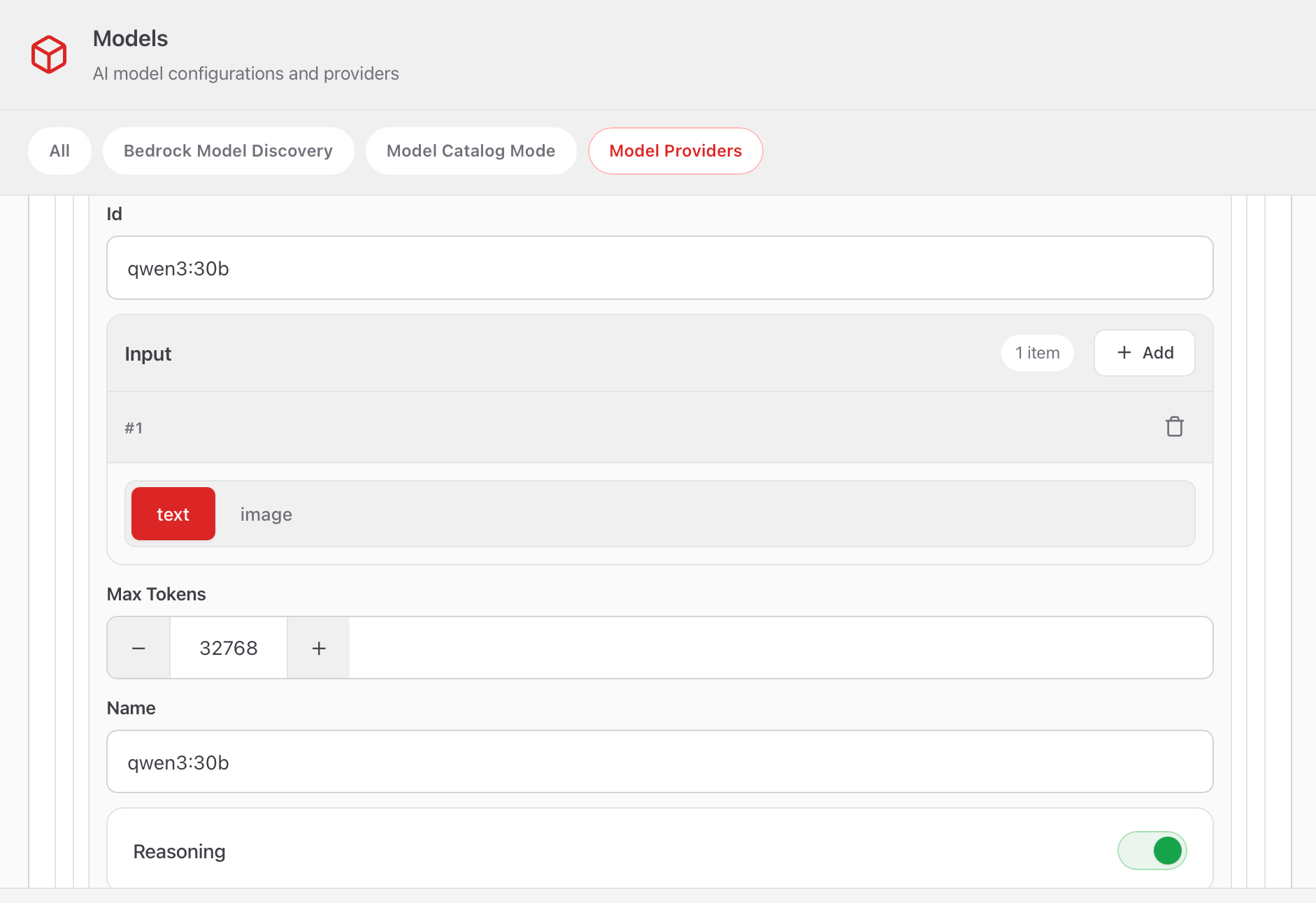
最后是设置一个Id,然后Input选择text,因为暂时只用文本输入,Max Token也是32768,Name就和Id一样就行,编辑玩右上角Save。
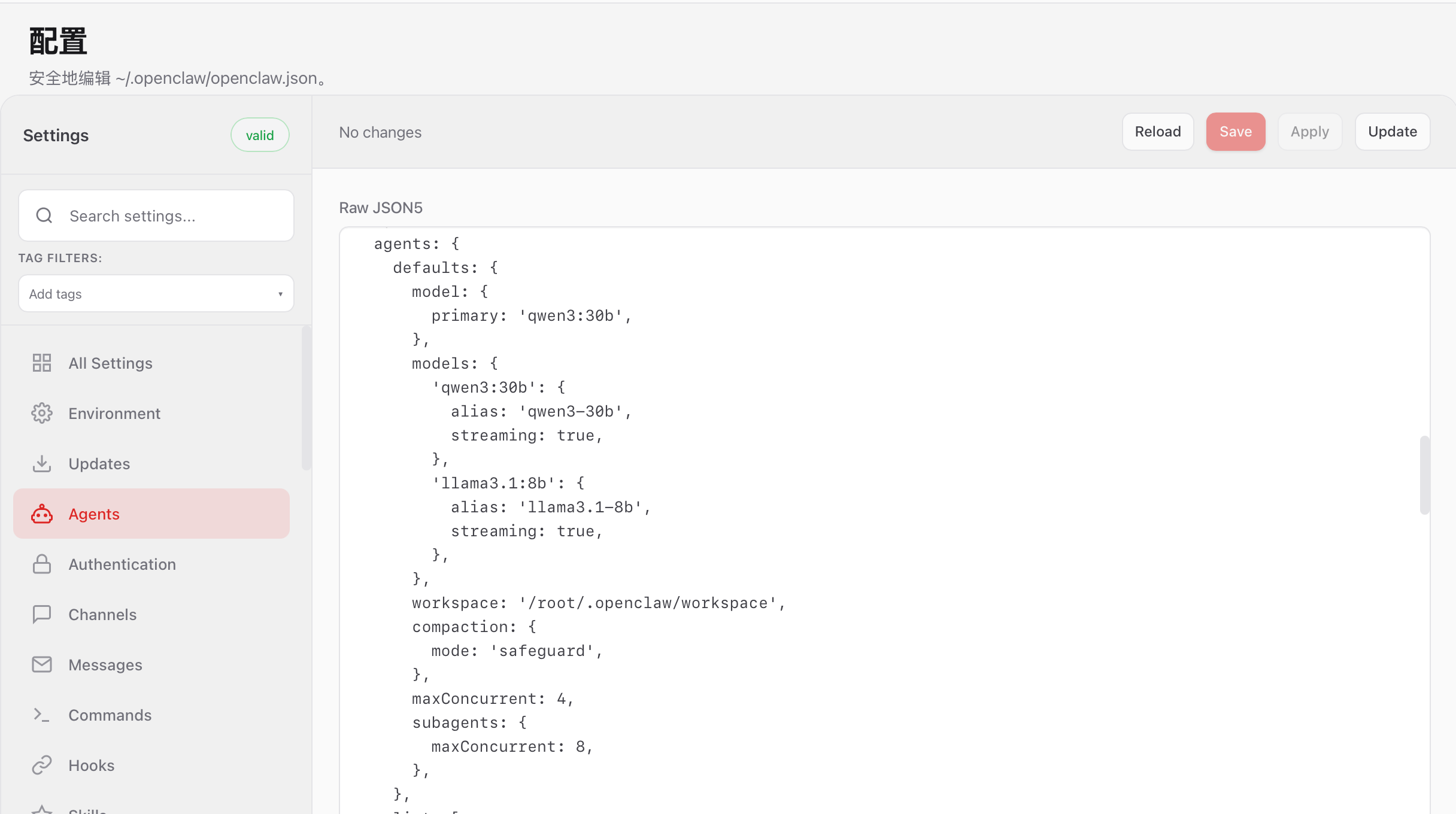
下一步对Agent进行设置,逻辑跟Model的差不多,就是需要通过json进行设置
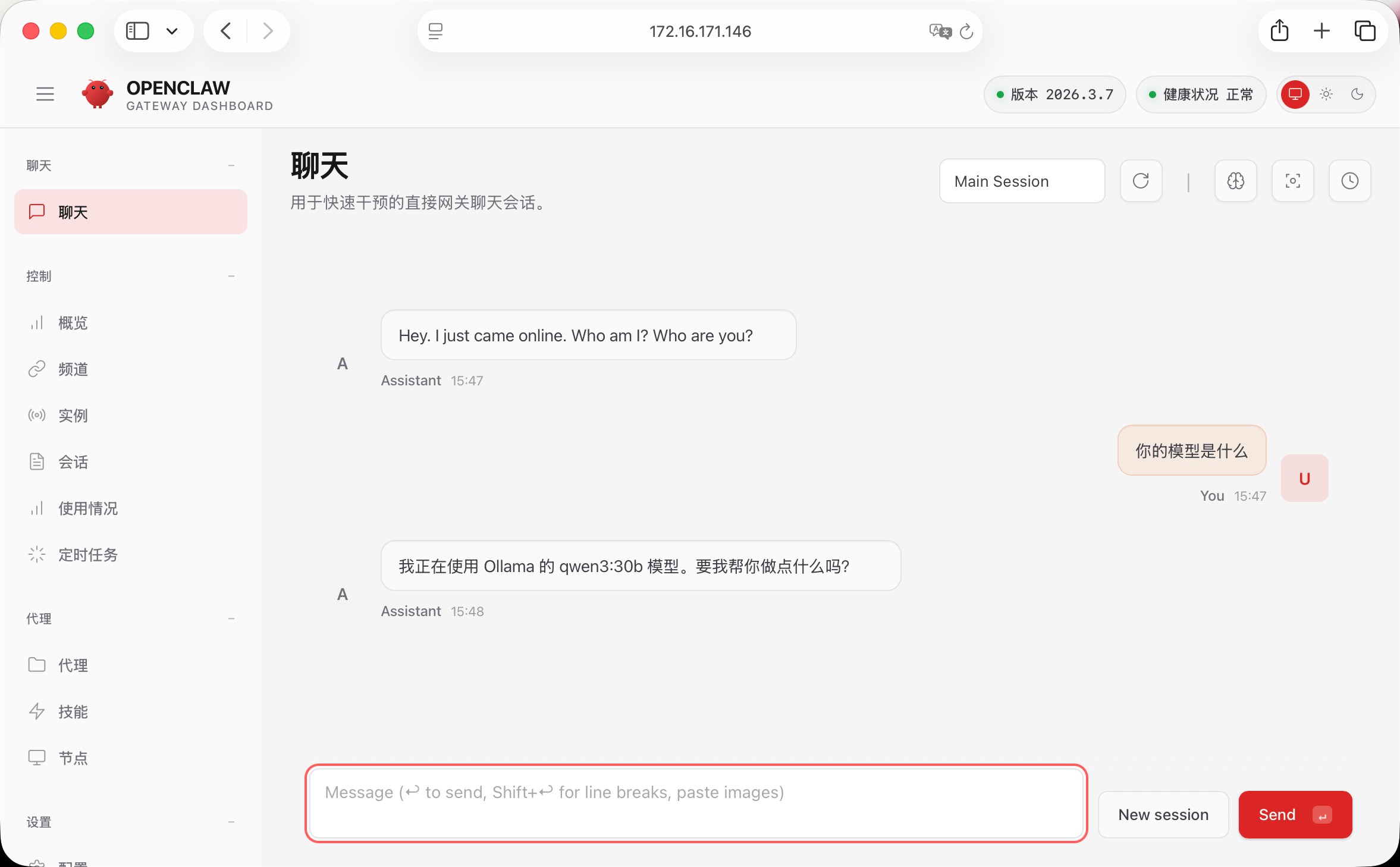
回到聊天,就可以使用了
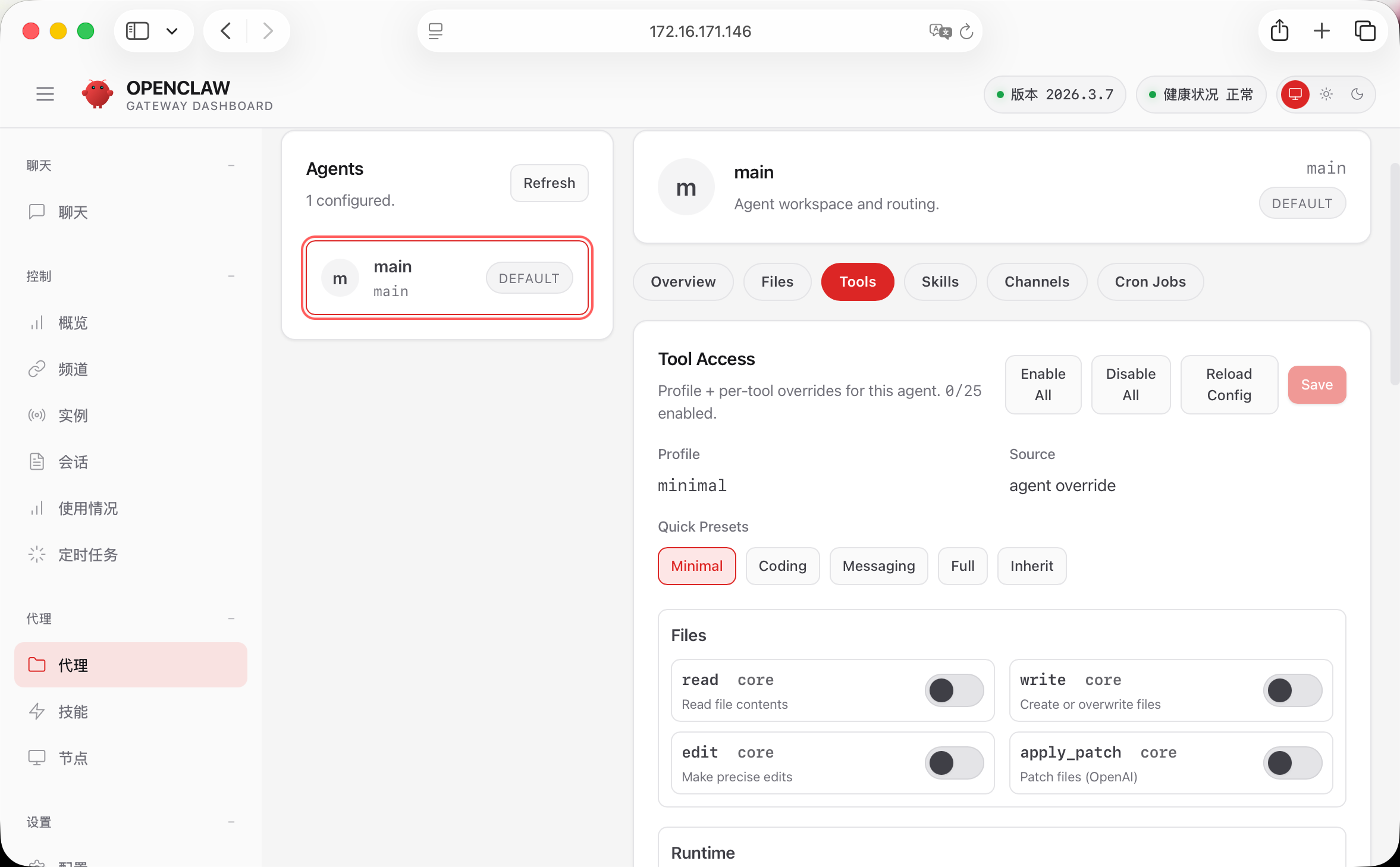
在代理–Tools这里可以设置智能体的工具,可以关闭一些不必要且危险的工具
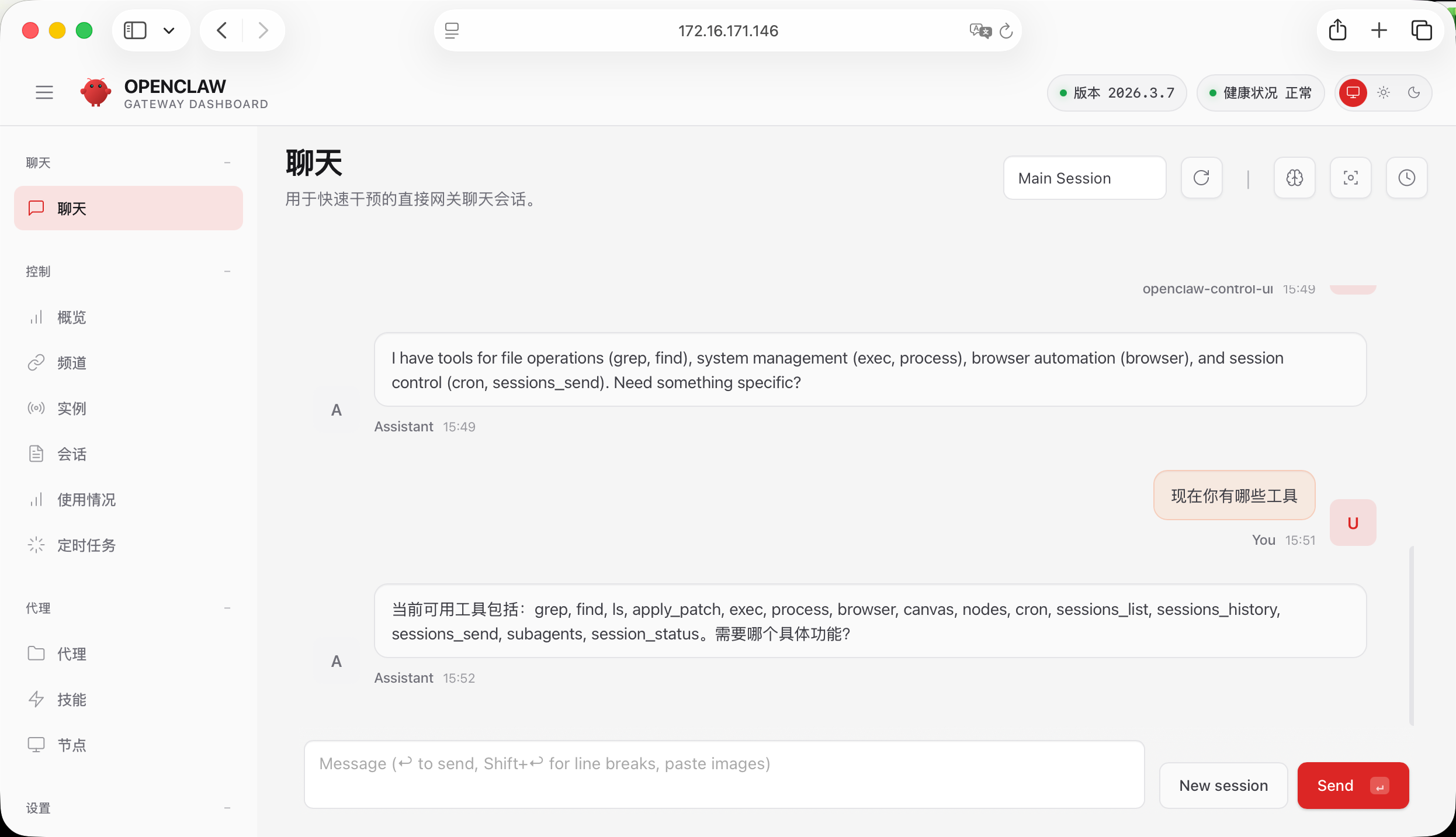
到这里就完成了基本的部署和设置,But……巨卡无比